Automating data extraction from password protected web sites
Many web sites containing sensitive information require the user to authenticate themselves by logging in. Authentication or session cookies (small pieces of data stored in the web browser) are the most common method used by web servers to know whether the user is logged in or not, and which account they are logged in with. Deleting cookies from the browser is equivalent to signing out. If you use the Data Toolbar, the cookies are deleted when the web browser is closed.
There are three ways in which the web scraping software can handle the password protected web sites: manual sign-in, sign-in using cookies and automated sign-in.
Manual sign-in
The sign-in is done manually before you start data collection. Each time you restart the browser, you need to repeat the manual sign-in. This is the default behaviour. It cannot be used for scheduled tasks.
Using authentication cookies
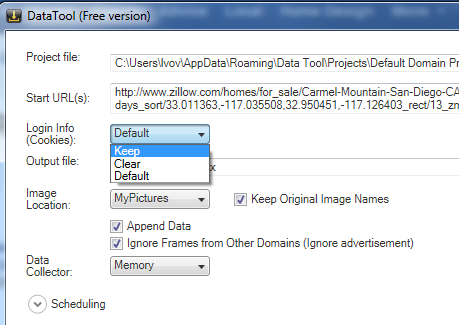
The sign-in is done manually only once before you start the Project Designer to build the project. That creates an authentication cookie in the browser. Then the project Cookies policy should be set to “Keep” using Project Properties screen. That instructs the crawler to keep and restore the current authentication cookie each time the program starts collecting data. Restoring the authentication cookies is a simple approach that works well for web sites that use persistent cookies (i.e. Amazon.com). It can be used for scheduled tasks.
Fully automated sign-in
The sign-in procedure is a part of the scraping project. The program does not require any previously created login information. This is the most reliable approach for a scheduled execution. It is important for the project to start clean to be processed always in the same manner. To force the clean “not signed” state, set the project Cookies policy to “Clear”. A log-in form can be automated as any other input form by selecting user name, password fields and the submit button.
Below is a step-by-step instruction to fully automate the sign-in procedure for Amazon.com.
- Using the browser navigate to the Amazon home page.
- Click the Data Tool button to open the Project Designer.
- In the Project Designer click the Project Properties link-button and then set Login Info (Cookies) combo-box to Keep.
- Press Done to save changes and return to the template designer screen.
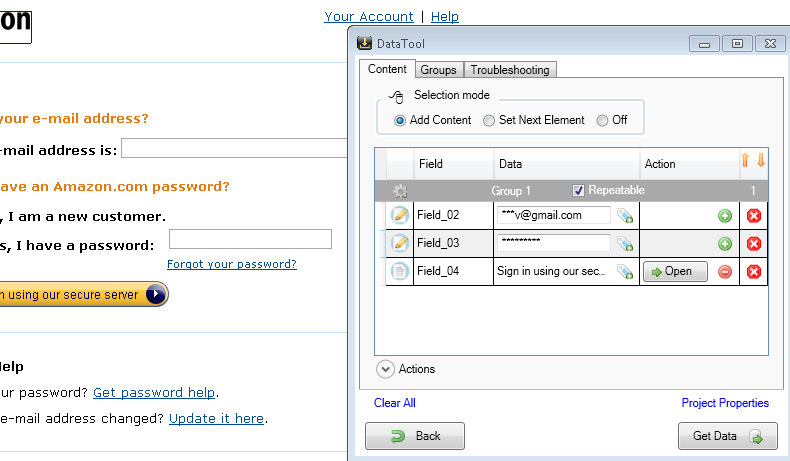
- On the web page select the Sign In link. That will create a new element in the template designer. Uncheck the Repeatable checkbox.
- Add an action to the Sign In element and click the Open button. The browser will navigate to the log-in form
- Select user name (e-mail), password and the Sign in button. Fill the user name and the password. Then press the Open button associated with the “Sign in...” element
- After the successful sign-in, complete the rest of project. For example, collect new orders.